Алгоритм поиска в яндексе
Доклад назывался "Базовые оптимизации". Представлял доклад Петр Попов.
Общий план доклада такой: будем двигаться с масштаба 1000 серверов, потом доберемся до 1 сервера, на котором запущена программа «Базовый поиск» – поэтому доклад и называется "Базовая оптимизация". Затем дойдем до самого низкого уровня, уровня ассемблера и горячих функций в поиске.
С 2000 по 2010 года число запросов выросло в 100 раз, а активность аудитории в тысячи раз. Т.е. это характеризует внешний рост, однако есть еще внутренний рост. При любом запросе мы ищем все формы исходного слова. Запрос расширяется и в одном представлении у нас получается очень большое количество терминов. Сейчас пользователи создают многословные запросы, а на низком уровне один запрос состоит из сотен, или тысяч термов. Один из аспектов роста – объем ранжирующей формулы.
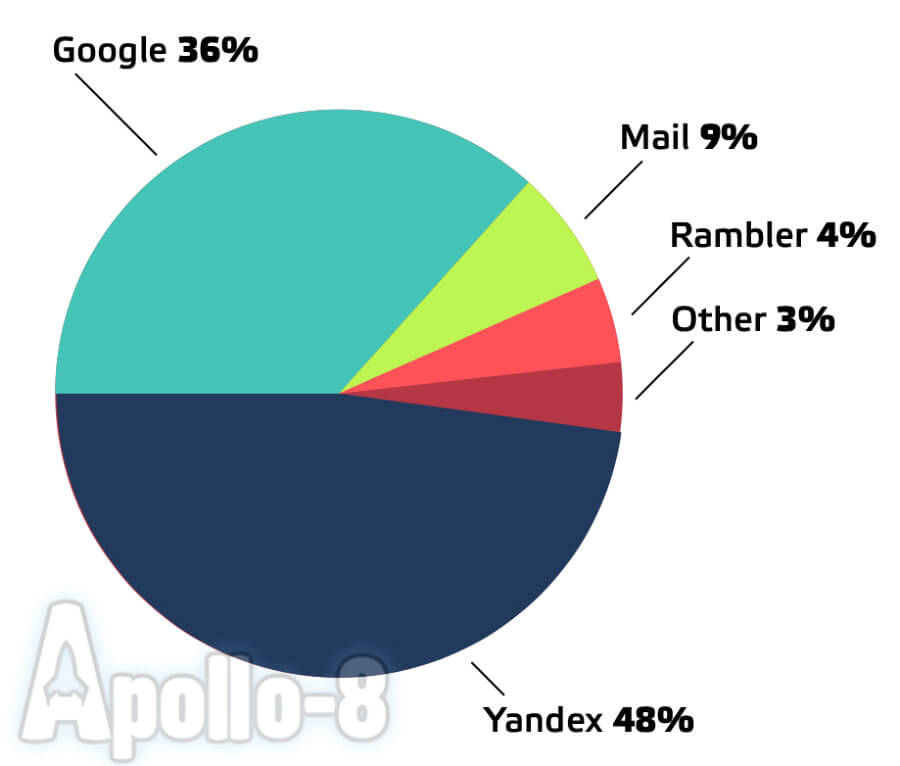
Популярность поисковой системы Яндекс в России
Еще один из факторов роста заключается в том, что документы, которые мы нашли, необходимо отранжировать, т.е. выставить в том порядке, в котором они будут в поисковой выдаче. Объем ранжирующей формулы более 120 мегабайт исходников. Однако формула не одна их больше 10, но меньше 100, т.к. для разных типов запросов и т.п. факторов будет своя ранжирующая формула.
Есть 2 проблемы внешнего роста – проблемы железа и проблема программинга. В итоге для снижения нагрузки равномерно должны решаться обе задачи.
Архитектура поиска - это пирамида:
1. Сверху пирамиды единичные сервера, обрабатывающие наш запроса. Верхпий мета поиск (единичные сервера) – то, что пользователь видит в выдаче Яндекса. Яндекс берет данные из нескольких источников (картинки, видео, новости и т.д., при этом источников больше 20). (Заметьте, что единичные сервера в процентах даже не измеряются).
2. Средний (5% парка) – кэширует выдачу и распределяет запрос по серверам базового поиска. Он берет запрос и распределяет по многим серверам и при этом кэшируется наиболее частоупотребимые запросы, т.е. более 50% запросов. Половина нагрузки расшивается именно с помощью среднего мета поиска.
3. Базовый поиск – 95% парка машин. Это самая низкоуровневая компонента и самая требовательная к ресурсам. Необходимо очень много серверов, т.к. в базовом поиске нужно проиндексировать нескольких миллиардов документов рунета, при этом каждый сервер держит лишь небольшую часть документов. При этом запрос ищется на каждой из машин, а результаты объединяются средним поиском.
Благодаря разбиению не несколько уровней происходит не только разбиение по серверам, но и разбиение по сервисам.
А поисковая программа – это еще более низкий уровень, т.е. слои в структуре поисковой программы.
Работа поисковой программы.
В начале мы из миллионов документов ищем кворум – т.е. документы кандидаты. Там где встречаются слова запроса, каждое слово запроса имеет вес и мы набираем слова, чтобы сумма весов была больше конкретной границы (т.е. кворум). После нахождения документов-кандидатов считаем для них промежуточную формулу ранжирования (т.е. насколько эти документы хороши и полезны). И только потом запускаем на небольшом множестве из сотен документов полную ранжирующую функцию (полная ранжирующая функция является очень тяжелой). И вся архитектура среднего уровня построена на том, что мы делаем вначале простые вычисления со многим числом документов, потом более сложные вычисления со средним числом документов и потом совсем сложные вычисления с небольшим числом документов.
Поиск документов-кандидатов.
1. У нас есть слово, мы должны сохранить информацию о нем: "номер документа" + "словопозиция" и необходимо записать это в виде линейной структуры. Для всех документов будет полезно, если числа будут упорядочены.
2. Номер документа 32 битное число (шард), т.е. номер документа в пределах одного шарда. Есть словопозиция – информация о вхождении слова в документ, т.е. порядковый номер в документе. Порядковый номер в документе - тоже 32 битное число (может включать информацию, например есть ли ключевое слово в тегах).
3. Структура постинг листа (или кишка) – для поиска документа по заданному запросу (для двухсловного запроса будет две кишки). Это и есть первые две стадии поиска: поиск документов-кандидатов (кворум) и фаст ранк (первоначальное ранжирование).
Первоначальный поиск – мы ищем не все слова запроса, а только релевантное подмножество, но алгоритм аналогичный, параллельно двигаемся по двум упорядоченным множествам и ищем совпадения.
Низкий уровень – уровень функций.
Уровень функций использует обратный индекс, обратный индекс занимает много места и в не сжатом виде никуда не помещается, поэтому используется сжатие низкобитного потока данных.
MatruxNet.
Матрикснет – функция, которая ранжирует документы по признакам. На вход поступает документ у которого есть какие-либо признаки.
Примеры признаков: в документе меньше 100 слов, в документе встретились все слова запроса, язык запроса совпадает с языком документа.
Для ранжирования используем дерево выбора: в узлах дерева выбора лежат признаки документа (да/ нет) и в зависимости от выбора мы идем по конкретной ветке, получая конкретные значения, спускаемся вниз по дереву. При этом выбираем конкретные значения в дереве решений.
Чтобы хорошо представить релевантность документа необходимо использовать тысячи деревьев выбора. Вычисление деревьев ресурсоемкая процедура, т.к. происходит вычисления по множеству деревьев. Яндекс использует другую схему, Яндекс балансирует деревья, он говорит что у дерева есть фиксированное число уровней и на каждом уровне свое условие (одно и то же). Например 3 уровня = 3 признака, внизу лежат значения. Элементарный терм – это массив, т.е. многомерный гипер куб по каждому измерению = 2. Т.е. получаем кубы информации. Преимуществом кубов является то, что можно произвести быстрый обсчет информации (не надо branchиться и можно бОльшую часть кода написать на потоковых расширениях на SSE). Если бы матрикснет потреблял 30-50% времени, то можно было бы купить специальные графические ускорители на которых деревья считаются очень быстро, но матрикснет занимает меньше процентов времени.
Если матрикснет реализовать на SSE (SSE может рассчитывать значения параллельно для 8 или 16 документов), то можно увеличить производительность в 4 раза.
Большое количество узловых точек на графике развития поискового алгоритма характеризуется тем, что каждый промежуток – это оптимизация кода на низшем уровне, или решали инфраструктурные проблемы, или просто рефакторили код.
Матрикснет, принцип ранжирования в Яндекс
Оставить комментарий
Комментарии:
А алгоритм по-итогу до сих пор не совершенен, раз выдает иногда черти-что?
Скорее даже алгоритм сделали удобным для самого поисковика, чем для пользователей. При этом в выдаче появляется то, что по мнению поисковой системы должно быть наиболее интересным пользователю. Однако, не всегда поисковые системы угадывают, что именно надо использовать по умолчанию для пользователя.