Анализ контента: от фантастики к реальности


Большой брат читает и понимает тебя
У фантастов компьютер будущего всегда понимал язык человека и даже разговаривал на нем.В реальности суть обработки естественных языков – получение новой структурированной информации из неупорядоченного набора текстов.
Я все прочитал по вашим губам.
Сверхразумный компьютер HAL 9000. Фильм «2001 год: Космическая одиссея» (1968)
Структурированная информация без проблем обрабатывается компьютером и может быть представлена в виде графиков, диаграмм и таблиц.
В чем сложность естественного языка? Вилка лежит, а тарелка при этом стоит, к тому же мы можем спросить о месте нахождения ресторана десятью разными способами. Не подскажите, как пройти к ресторану N? А вы случайно не знаете дорогу к ресторану N? Подскажите, пожалуйста, где тут N?
И как машине разбираться во всем этом? Текстовая аналитика спешит на помощь!Ее задачи:
- информационный поиск
- категоризация текста
- извлечение информации
Ода эффективности текстового анализа
Анализ текста – процесс трудный. И где-то в голове логичный вопрос – «зачем так сложно?» Продвигали же раньше и продвигают теперь, рассчитывая плотность ключевиков.
Сотрудники Яндекса сообщили, что из 800 факторов ранжирования около 50 – текстовые. Такое многообразие делает зависимость нелинейной. Следовательно, работа только с одним фактором даст положительный результат только при большой удаче.
Популярная формула BM25 имеет внушительный вид, но в итоге это просто более усложненный вариант расчета плотности ключевиков. Текстовый анализатор заходит с другой стороны – не пытается угадать алгоритмы, которые регулярно меняются и неодинаковы для различных запросов. Он анализирует успешные страницы и помогает понять, как войти в их число.

ТОП сегодня зеленый – мимикрируем
Для большей наглядности посмотрим на результаты эксперимента, проведенного для конференции IBC Russia. Было выбрано пять коммерческих сайтов разной тематики, и страницы каждого были поделены между двумя подходами к оптимизации – текстовым анализом и подсчетом вхождений через BM25.
Для низкоконкурентных запросов оба метода показали высокий результат, который различался в пределах погрешности. Но уже при работе со среднеконкурентными запросами формула BM25 показала снижение вместо повышения, с высококонкурентными – вообще стала причиной ухода из топа. При этом текстовая аналитика подняла видимость страниц на 14% и 7% соответственно.
Чтобы проверить частотность запросов – используйте анализ слов в Яндексе.
Текстовый анализ как инструмент оптимизации
Задача текстовой оптимизации – подстроиться под требования поисковика по запросам. Для этого вычисляется «окно допустимых значений» – число вхождений фраз из запроса в различные блоки страницы, позволяющие ей попасть в ТОП. Речь идет о содержании тегов. Иногда оптимизаторы бездумно «пихают» ключевые слова где ни попадя или, наоборот, мало их используют.
Посмотрим на следующую таблицу.

Пример числа вхождений по тегам
Во-первых, оптимизатор переборщил с зонами text-fragement (содержимое небольших текстовых фрагментов) , plain-text (содержимое всего текста). Во-вторых, неправильно разместил вхождения: большинство запросов расположено в text-fragement и plain-text, а должны быть в теге <a>. Это позволит распределить число вхождений.

Налево пойдешь – в ТОП не попадешь, направо пойдешь – из ТОПа вылетишь
Начинается все с текстового анализа с цельюпоставить задачу копирайтеру.Вхождения подсчитываются и самостоятельно, но с тем же успехом можно вручную копать котлован – результат будет получен, но уйдет больше времени, а качество будет хуже.
Будни текстового аналитика
Существует два способа текстового анализа. Разберем каждый из них.
1. Анализ по одному запросу: палка о двух концах
Не учитываются витальные ответы (официальные сайты брендов)и заведомо высоко ранжируемые сайты (например, Википедия). Затем запрос разбивается на все возможные вхождения: прямые, точные и разбавленные. Точные пишутся в строке поиска без изменений: с тем же порядком слов и с той же словоформой. Например, у нас есть ключ «организация корпоративов». Получаем следующий результат.
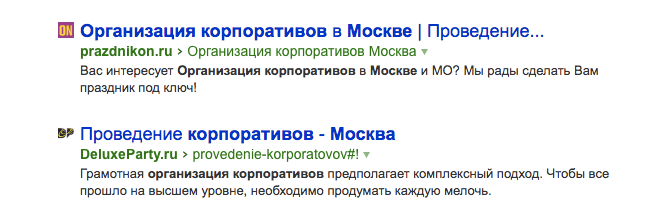
Пример точного вхождения
В прямых вхождениях могут встречаться знаки препинания, но словоформа будет та же. Берем запрос «торты на заказ» и получаем: «В нашей кондитерской можно купить любые торты: на заказ по вашему рецепту, классические или фирменные.»
В случае с разбавленными вхождениями изначальный «ключ» изменяется как угодно.

Было «торты на зазказ», стало – «на заказ тортов»
Какие вхождения лучше? Получается «палка о двух концах»: точные вхождения делают страницу релевантнее, так как полностью соответствуют запросу пользователя. Но если весь текст будет состоять из слов в именительном падеже, его будет невозможно читать.
Оптимальное решение: использовать точные и прямые вхождения в заголовке и подзаголовках, а разбавленные – в основном тексте.
2. Анализ по нескольким запросам – задача для продвинутых
Усложняем задачу. Чаще на страницу продвигается более одного запроса. Секрет успеха в «упаковке» одних вхождений в другие, а их совместимость определяется правильной кластеризацией (поисковик диктует свои условия, а кластеризация выявляет совместимые запросы). Необходимо искать, на какие страницы приводит определенная группа слов, а не строить работу вокруг основного – совместимые с ним запросы могут исключать друг друга. Такой способ называют кластеризацией, о которой мы расскажем в следующем разделе.
Курение вредит вашему здоровью!
Когда ведется работа с несколькими запросами, диапазон вычисляется для каждого отдельно. Вхождения на странице по одному запросу суммируются, и получается формально идеальный набор вхождений для попадания в ТОП.
Не стоит воспринимать результат текстового анализа как готовое техническое задание для копирайтера. К примеру, анализатор скажет, что для низкоконкурентного запроса вообще необязательно точное вхождение, потому что в ТОПе нет релевантных страниц. Тут человек должен понять, что это возможность не просто подстроиться, а сделать сайт лучше и занять верхние строчки.
Кластеризация запросов – инструмент №1
Кластеризация запросов – это разделение ключевых слов на группы (кластеры) по определенным признакам. Такое распределение позволяет быстрее продвинуть сайт на первые позиции выдачи за счет текстов и статей. Осуществляется кластеризация, исходя из схожести результатов поиска для различных запросов.
Зачем это нужно?
- Для быстрой и эффективной проработки семантического ядра
- Для устранения из СЯ ненужных запросов
- Чтобы понимать, какие запросы могут вести на одну страницу
- Для построения структуры сайта
Распределить ключевые слова по группам можно как вручную, так и автоматически. Приведем список компаний, которым точно можно доверить кластеризацию:
- TopSite
- JustMagic
- Rush Analitics
- Key Collector
- Topvisor
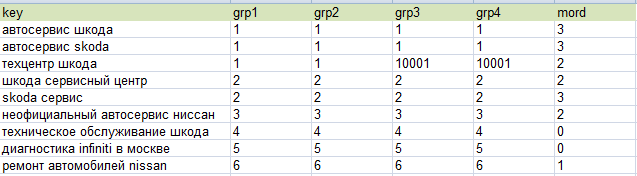
Пример кластеризации запросов
Как видим, все запросы распределены на несколько групп. Grp1 — кластеризация по 3 урлам, grp2 — по 4м урлам, и.т.д. Последний столбец «mord» - «тематическая» группировка.
grp1 — это наиболее широкая группа (сформировання по 3м урлам). Это означает, что все запросы, имеющие одинаковый номер группы в столбце grp1, относятся к одной группе. Группа формируется по принципу «существует как минимум 3 урла, которые присутствуют в топ-10 по каждому из запросов группы». Grp2-4 созданы по аналогичному принципу, но минимум урлов для объединения у них 4-6.
Текстовые факторы ранжирования сайта Яндексом
В 2014 году Яндекс отключил ссылочное ранжирование, и теперь seo специалисты вынуждены уделять больше внимания текстовым факторам. Ведь именно от оптимизации текста зависит выведение сайта в ТОП.
В Яндексе существует более 400 текстовых факторов ранжирования! Поделимся с вами секретной табличкой алгоритмов. Спорим, вы знаете далеко не все?
1. Текстовая релевантность
Название фактора | Краткое описание |
TR | Текстовая релевантность (maxfreq – частота самого частого слова, которая имеет смысл длины документа). |
PrBonus | Prioritybonus, приоритет 7 – текстовый приоритет. Фактор бинарный, имеет значение 0 для всех однословных запросов, и значение 1 практически для всех двух и более словных, кроме очень маленького количества ответов, для которых нет ни одной ссылки, прошедшей кворум, и текст тоже не прошел кворум. |
TRp1-2 | Приоритет strict для TR – текстовый приоритет – есть все слова запроса где-то в документе (при этом они проходят контекстные ограничения запроса, например, оба слова должны быть в одном предложении). |
TRtitle | Наличие точной фразы (текста запроса) в заголовке (если точнее, в первом предложении документа). Контекстные ограничения и стоп слова учитываются в точности как в TRp2. |
TRhr | Встретился участок, прошедший кворум, в котором все словопозиции обозначены как имеющие релевантность BEST_RELEV (заголовок или metakeywords). |
TRhitw | Hitweigt – вариант текстовой релевантности, в которой веса всех хитов считаются равными (т.е. не учитывают надбавки за title и за близость слов). |
TRref | Фактор про число refines. В языке запросов есть фича userrefines ("слово, перед которым стоит знак процентика"). По задумке это означает что-то вроде "хорошо бы, чтобы слово в документе было". Пользователям данная фича неизвестна, т.к. не описана ни в какой документации. Планируется, что она исчезнет из языка запросов, но в колдунщике слова с приоритетом USER_REFINE останутся. Фактор говорит о том, сколько максимум USER_REFINE-слов одновременно встречалось в рамках единого попадания в кворум. Считается, что их от 0 до 3 (если >3, то считается, что 3). |
TRboost | Число, на которое умножаются некоторые линковые факторы, если текстовая релевантность 0, и ссылок мало. |
TRLRlemma | В текстовой релевантности произошло совпадение леммы. |
TextBM25 | Простой BM25 по тексту. |
TxtPair | Простой BM25 по парам слов – берем все пары слов запроса и считаем число их вхождений в текст документа. В качества веса пары используем сумму весов слов. Не работает, если в запросе есть стоп-слово. |
TxtPair_W1 | Простой BM25 по парам слов – берем все пары слов запроса и считаем число их вхождений в текст документа. Вес =1. Не работает, если в запросе есть стоп-слово. |
TxtPairEx | Наличие пар слов по точной форме. |
TxtPairSy | Наличие пар слов c учетом синонимов (>=TxtPair). |
TxtBreak | BM25 от количества предложений в документе, в которых встречается. |
TxtHead | BM25 по словам только в заголовке. |
TxtHeadEx | Наличие слов в заголовке по точной форме. |
TxtHeadSy | Наличие слов в заголовке c учетом синонимов. |
TxtHiRel | BM25 по словам только с highrel-битиками. |
TxtBreakEx | Количество предложений, в которых встречается много слов по точной форме. |
TxtBreakSy | Количество предложений, в которых встречается много слов c учетом синонимов |
HasNoAllWordsTRSy | В документе нет всех слов запроса (с точностью до синонима). |
HasAllWordsTRSy | В документе есть все слова запроса (с точностью до синонима). |
LargestSyInexactGroup | Доля запроса, покрываемая самой длинной группой, состоящей из любых хитов (в т.ч. словоформ и синонимов). Возможно, с пропуском, добавлением или заменой слова. |
QSegmentsBreaks | Сегменты запроса – это части запроса, которые сами по себе являются частотными запросами. Фактор показывает, насколько сегменты бьются в тексте. Значение 0 – все слова встречаются только в рамках обозначенных сегментов, 1 — все вхождения разбивают сегменты |
QSegmentsBM25 | BM25, где в качестве "слов" выступают выделенные сегменты запроса. |
QSegmentsWeight | "Вес" сегментов запроса в тексте. |
TextForms | Невзвешенная сумма числа форм – сумма по всем словам запроса числа_форм_для_слова/64/число_слов_запроса |
HasTextPos | У документа есть текстовая релевантность |
SWBM25 | Хитрый BM25 в скользящем окне. Размер окна задается в предложениях. Используются «джокеры» для заголовков и начала документа. Учитывается морфологическая близость и структура текста. Вес окна затухает с удалением от начала документа. |
FieldLM | Униграммная языковая модель. Моделируется языковая по документу, сглаживается общеязыковой моделью. При построении модели по документу используется информацию о том, в каком поле документа встретилось слово запроса (Title, head или plaintext) |
YmwFull | Размер минимального куска текста, включающего все встречающиеся в документе слова запроса. Сейчас не используется. |
Bclm | Фактор имени Buettcher, Clarke и Lushman (модифицированный) |
TitleTrigramsQuery | Вычисляет покрытие запроса буквенными триграммами заголовка документа |
TitleTrigramsTitle | Вычисляет покрытие заголовка буквенными триграммами заголовка документа |
AbsolutePLM | Текстовая релевантность на основе языковой модели, учитывающая абсолютную позицию. Идем по тексту с окошком 20 слов, строим по каждому окошку языковую модель (то есть распределение вероятностей на словах русского языка) и вычисляем вероятность порождения запроса. За удаление от начала документа штрафуем модель. |
QueryWordCohesionTR | Фактор оценивает как слова запроса группируются друг с другом в тексте документа без учета их порядка. |
DBM25_2 | Вариация на тему DBM25 |
Tocm | Фактор оценивает отличия позиций слов в заголовке от позиций слов в запросе. |
DBM30Smerch | Вариация на тему DBM25 |
BOCM | Оценивает соответствие позиций слов в предложениях документа по позициям слов в запросе. |
FioMatch | В документе присутствует ФИО из запроса. |
BclmMax | Близость слов запроса к самому тяжелому слову. |
2. Антиспам
Название фактора | Краткое описание |
NoSpam | Классификатор спама по фичам из антиспама признал сайт НЕ(!) спамом. Т.е. 0=спам, 1=хороший. |
Spam2 | Автоматичемкий классификатор спама им. Алексеева, вероятность того, что сайт спам (0 не спам, 1-спам) |
IsLinkPessimised | Антиспамеры пессимизировали сайт – все динамические линковые факторы обнуляются. |
RingsHostRankBadnessOld | Характеризует раскрученность сайта линковыми кольцами. Значение – доля внешних ссылок, которые входят в линковые кольца и линкообменники. |
CInDegree1-2 | Хостовые факторы, определяют сайты, накрученные линками – вторая и третья входящие степени. |
CommLinksSEOHostsPornoQuery | Предыдущий фактор умноженный на PornoQuery |
CommLinksSEOHostsNonComm | Фактор CommLinksSEOHosts умноженный на NonCommercialQuery |
SeoInPayLinks | Количество входящих сео-треш ссылок между хостами |
RankComGoodness | Классификатор по оценкам коммерческих сайтов |
CommercialOwnerRank_Reg | Классификатор коммерческости сайта (Россия и Турция) |
3. Вторконтент
Название фактора | Краткое описание |
AuraDocLogShared | Логарифм числа шинглов, на которых данный документ не уникален |
AuraDocLogAuthor | Логарифм числа шинглов, на которых данный владелец документа признан автором |
AuraDocLogOrigin | Логарифм числа шинглов в документе, добавленных хозяином сайта как оригинальные тексты в Плагин Оригинальности. В формуле не участвует, нужен для переранжирования дублей |
AuraDocMeanSharedWeight | Средний вес неуникальных шинглов данного документа |
AuraDocMeanFltAuthorSource | Среднее фильтрованное число источников авторства документа. В формуле не участвует, нужен для переранжирования дублей |
AuraOwnerLogUnique | Логарифм числа уникальныхшинглов на данном владельце |
AuraOwnerLogShared | Логарифм числа шинглов, на которых данный владелец не уникален |
AuraOwnerLogAuthor | Логарифм числа шинглов, на которых данный владелец признан автором |
AuraOwnerLogUnauth | Логарифм числа шинглов, на которых данный владелец не является автором (и автор определён) |
AuraOwnerMeanSharedSpread | Среднее число владельцев у не-уникальныхшинглов данного владельца |
AuraOwnerLogOrigin | Логарифм числа шинглов на владельце, добавленных хозяином сайта как оригинальные тексты в Плагин Оригинальности. В формуле не участвует, нужен для переранжирования дублей |
4. Качество текста, распознавание спама, машинного текста
Название фактора | Краткое описание |
SynPercentBadWordPairs | Показатель неестественности текста с точки зрения русского языка. Число плохих пар слов в тексте, перенормированное в отрезок [0,1] по формуле z/(z+10) |
SynNumBadWordPairs | Доля плохих пар среди всех найденных в таблице: z/(x+1), где z – число плохих пар в тексте, а x – число 2000-релевантных пар |
RusWordsInText | Число слов в тексте (Слово – то, что выделил леммер), отображается в [0,1] по формуле x/(x+A) |
RusWordsInTitle | Число слов русского языка в заголовке |
MeanWordLength | Средняя длина слова |
PercentWordsInLinks | Процент числа слов внутри тега <a>..</a> от числа всех слов |
PercentVisibleContent | Процент числа слов вне тегов (вне скобок <>) от числа всех слов |
PercentFreqWords | Процент числа слов, являющихся 200 самыми частыми словами языка, от числа всех слов текста |
PercentUsedFreqWords | Число использованных в тексте 500 самых популярных слов языка, деленное на 500 |
TrigramsProb | Логарифм среднего геометрического вероятностей триграмм в тексте. (вероятность триграммы – число ее встречаний в тексте, деленное на число всех триграмм), отображается в [0,1] по формуле -x(x+A) |
TrigramsCondProb | Логарифм среднего геометрического условных вероятностей триграмм.условная вероятность триграммы – ее вероятность, деленная на вероятность биграммы из первых двух слов |
NumeralsPortion | Доля разных частей речи в тексте.доля числительных (среди всех слов, у которых удалось распознать часть речи) |
ParticlesPortion | доля частиц |
AdjPronounsPortion | доля местоименных прилагательных |
AdvPronounsPortion | доля местоименных существительных |
VerbsPortion | доля глаголов |
FemAndMasNounsPortion | доля слов, которые могут быть как существительными мужского рода, так и существительными женского рода, но не среднего рода, среди всех существительных (примеры: "колибри" – пример неопределённого рода, который можно определять двумя способами, "Александра" – омонимия). |
Команда Аполло-8 знает все перечисленные алгоритмы и использует их для текстового анализа наравне с Яндексом. Чего и вам советуем!
Выделим две особенности текстового ранжирования Яндексом:
- В поиске используется большое число текстовых факторов, не собранных в единую формулу.
- Под каждый запрос или группу запросов есть своя формула.
Погоня за формулой ранжирования – путь непродуктивный, потому что она корректируется рядом способов.
- Пользовательское поведение – определяющий фактор, к которому сводятся все остальные. Как часто пользователи кликают на результат, сколько времени проводят на сайте, добавляют ли страницы в закладки, делают ли репосты.
- Асессоры – сотрудники, которые оценивают качество и релевантность сайта с человеческой точки зрения. Так обучается Матрикснет – искусственный интеллект Яндекса, строящий формулу ранжирования.
Персонализация выдачи в соответствии с личными предпочтениями пользователя, т.е. выдача для двух разных пользователей не будет одинакова.
Судьи сайта — это не поисковые системы, а пользователи. Поисковые системы всегда подстраиваются под потребности пользователей, стремятся предсказать, что будет для них полезно.
Александр Садовский, руководитель поисковых сервисов Яндекса
- Заголовок страницы в выдаче – содержание тега <title>, которое должно быть интересно и информативно для пользователя. Для корректного ранжирования обязательно надо проставить теги заголовков <Н1> или <Н2>, но не забывать, что они должны соответствовать структуре текста.
- При поиске по картинкам учитывается не только сама иллюстрация, но и текст рядом с ней. Особенно актуально это для коммерческих проектов, потому что пользователю бывает удобно сначала посмотреть на товар, а потом перейти на сайт продавца, а не последовательно изучат каждую ссылку из выдачи.
Какие параметры должен учесть оптимизатор, чтобы с помощью текста вывести сайт в топ?

Царь, просто царь
- Релевантность. Текст должен максимально соответствовать запросу. На странице должно быть меньше общих слов и больше узкотематических. Например, для стоматологии это будут названия болезней и предлагаемых процедур.
- Отсутствие «воды». Не нужно растекаться мыслью по древу – говорите конкретно о конкретных вещах.
- Отсутствие спама и «тошноты». Не перегружайте текст ключевыми словами – они могут не только сделать сайт нечитаемым, но и привести его к фильтру «Переспам».
- Практическая полезность. Пользователь получает инструкцию, определение, ответ, который искал.
- Актуальность. Устаревшая информация повлечет за собой высокий уровень отказов.
- Надежность. Пользователь предпочитает проверенную информацию: мнения профессионалов, авторитетные источники, отзывы укрепляют доверие.
- Уникальность. Яндекс не замедлит с понижением в выдаче, если контент окажется вторичным или заспамленным.
- Естественность и грамотность. Алгоритмы Яндекса на страже великого и могучего – текст должен соответствовать всем правилам русского языка. Машинный текст для человека не читаем, и легко выявляется компьютером.
Как провести текстовый анализ самостоятельно? Проверка текста на уникальность и не только…
Провести качественный анализ текста можно с помощью нескольких онлайн-сервисов. Расскажем, как и в какой последовательности их использовать.
1. Text.ru (https://text.ru)
Скопируйте свой текст в специальное окно – и вы получите сведения об уникальности статьи, заспамленности и «воде».
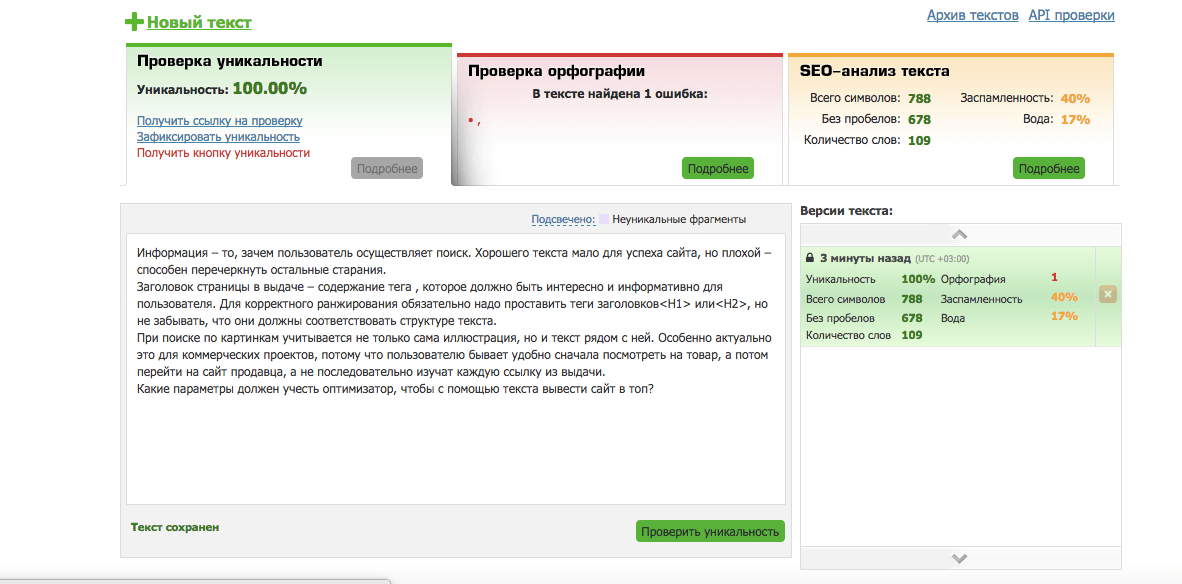
оптимальный процент уникальности – более 90%
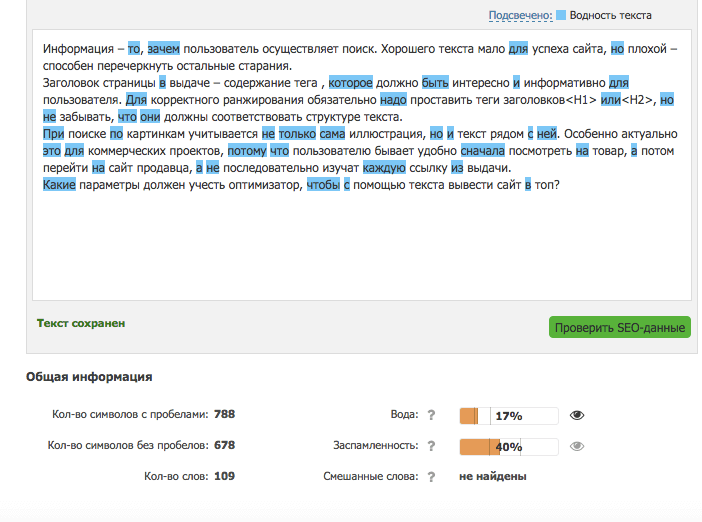
Прокрутите страницу вниз – и вы увидите кнопки в виде глаз. Кликнете по ним, и сервис выделит ненужные слова. А так же те, которые говорят о заспамленности текста.
Убираем «воду»
Как видим, процент «воды» в этом тексте небольшой, а некоторые слова невозможно выкинуть из предложения: иначе оно потеряет смысл. Поэтому в целом мы можем оставить все так, как есть.
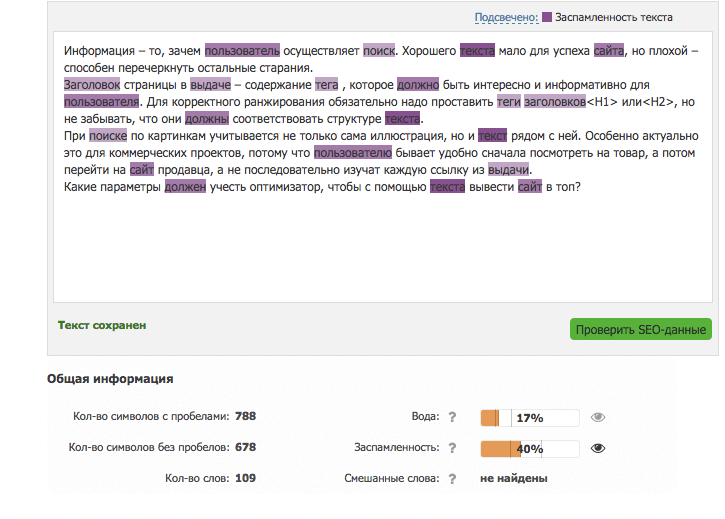
Избавляемся от спама
Для маленького абзаца 40% - плохой показатель. Получилось много повторов, и от них нужно избавиться.
2. PR-CY (http://pr-cy.ru/analysis_content/)
Теперь, когда мы избавились от «воды» и спама, проверим текст с точки зрения оптимизации. На странице сервиса нужно ввести список ключевых слов и разместить ссылку на проверяемую статью.
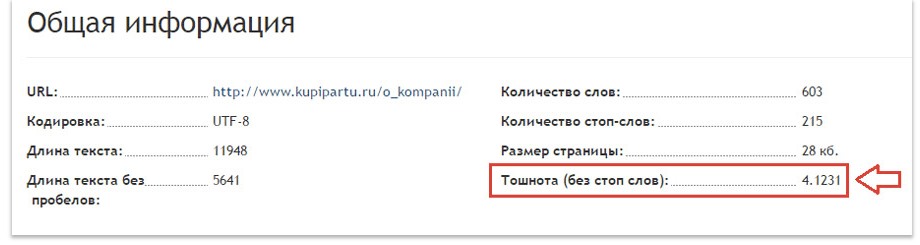
Показатель «тошноты»
Оптимальный показатель «тошноты» – 5-8%. Если меньше – текст мало оптимизирован, больше – переоптимизирован.
Далее проверяем плотность ключевых слов.
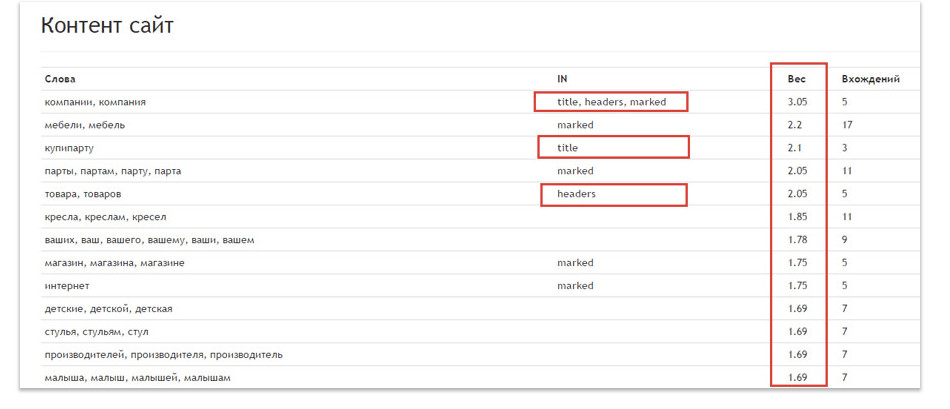
Всё четко!
Слова с пометками title, headers и marked должны иметь вес в пределах 2-5. Здесь снова важно соблюсти тонкую грань между недостаточной оптимизацией и переспамом.
3. Главред (https://glvrd.ru)
И на последнем этапе проверим текст с точки зрения полезности для читателя.
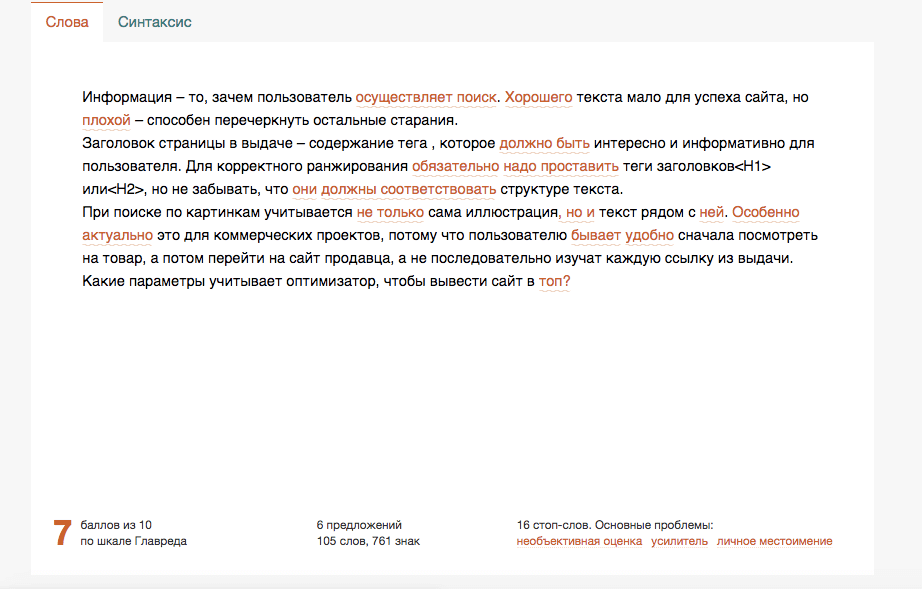
Сервис «Главред» - лучший друг копирайтера
«Главред» создан известным блогером Максимом Ильяховым, который пишет книги о копирайтинге и читает обучающие лекции.
Хорошая оценка – 7 и более баллов. Если вам поставили меньше, статья вряд ли будет интересна читателям. Все ошибки выделены волнистой линией. При наведении на них вы увидите сбоку пояснения о том, что не так и как это исправить.
Курс на всплытие
Подходит к концу сегодняшнее погружение в текстовую аналитику – мощнейший инструмент на базе искусственного интеллекта, который полезен для решения самых разнообразных задач.
Как вы поняли, из-за алгоритмов Яндекса классификация запросов и их продвижение на одной странице зачастую не поддаются логике. Поэтому без огромного труда, вложенного в анализ, и без опыта продвижения сложно добиться реальных результатов. Этот «швейцарский нож» должна направлять умелая рука SEO-специалиста.
Оставить комментарий
Комментарии:
Мне как то заказ делал парень с проектом - вывести сайт из-под АГС на котором около 1.5 тыс статей, уникальность 10% максимум :)))